Elasticsearch 路由计算&分片控制
 金鹏
2021-12-06 22:12:46
金鹏
2021-12-06 22:12:46
导读:路由计算当索引一个文档的时候,文档会被存储到一个主分片中。Elasticsearch如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片...
路由计算
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
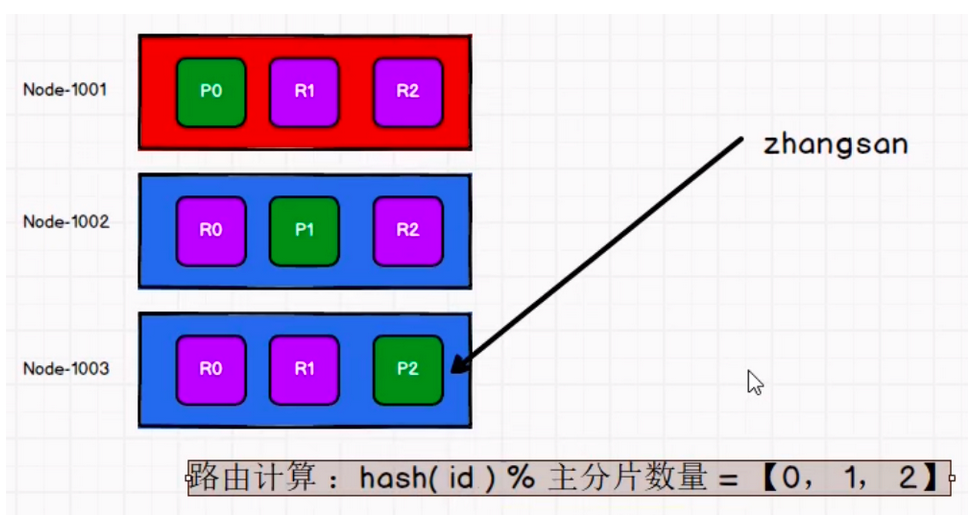
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
所有的文档API ( get . index . delete 、 bulk , update以及 mget )都接受一个叫做routing 的路由参数,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档—一例如所有属于同一个用户的文档——都被存储到同一个分片中。
分片控制
我们可以发送请求到集群中的任一节点。每个节点都有能力处理任意请求。每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。在下面的例子中,如果将所有的请求发送到Node 1001,我们将其称为协调节点coordinating node。
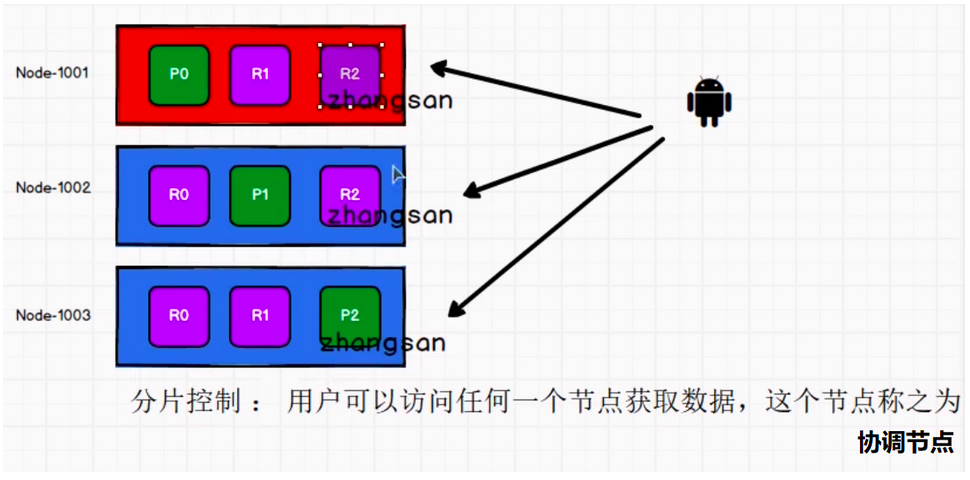
当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
本文地址:https://www.jinpeng.work/?id=45
若非特殊说明,文章均属本站原创,转载请注明原链接。
若非特殊说明,文章均属本站原创,转载请注明原链接。

相关推荐
欢迎 你 发表评论:
- 周排行
- 月排行
-

FFmpeg 视频转场Xfade
2021-11-02 -

ffmpeg 给视频加字幕:指定字幕位置
2023-04-06 -
FFmpeg 解决合并视频没有声音的问题
2021-10-29 -
Swoole4 [进程管理] 单进程(Process)
2022-01-02 -

Git常用命令
2021-10-25 -
Swoole4 高性能共享内存 Table
2022-01-02
-
FFmpeg 视频转场Xfade
2021-11-02 -
ffmpeg 给视频加字幕:指定字幕位置
2023-04-06 -
FFmpeg 解决合并视频没有声音的问题
2021-10-29 -
Swoole4 [进程管理] 单进程(Process)
2022-01-02 -
Git常用命令
2021-10-25 -
Swoole4 高性能共享内存 Table
2022-01-02
最近发表
-
Logstash 同步MySQL到ES
2025-04-08 -

Logstash 使用
2025-04-08 -
Vue3 自定义hook
2024-10-07 -
Vue3 生命周期
2024-10-07 -

Vue3 核心语法
2024-10-07 -
Vue3 初识
2024-10-07 -
Typescript 泛型
2024-10-07 -

Typescript 类相关
2024-10-07 -
Typescript 类型
2024-10-07 -
Typescript 初识
2024-10-07
